Hello!
With the release of Windows Server 2016 and the “great/awesome/fabulous feature” storage spaces direct(S2D) that has the concept of leveraging local storage to build a “virtual-san”, with different storage type from SAS/SSD/NVMe to generate different storage tiers/caching that can be both applicable on the cloud and on premises, this is game changer for SQL, both from a deployment perspective(automation) and cost vs performance !
How could one start to know a little bit more about this feature of Windows Server 2016? Start Here.
Architecture example for a converged solution:

The first steps towards building our SQL Server Always On Failover Cluster Instance with powershell!
In the cloud (Microsoft Azure):
Make sure we have our SQL Server VMs running in the same availability set to handle planned and unplanned maintenance and for the VMs not to run on the same rack/ network switch, meaning each VM will be assigned to an Update Domain (UD) split accross Fault Domains (FD) :

New-AzureRmAvailabilitySet -ResourceGroupName PauloCondecaInfraRG01 -Name SQLServerFCIAvailabilitySet01 -Location "westeurope"
After the Availability Set created, it is time to create our storage account… SQL Server loves Premium Storage 🙂
#PremiumStorageAccount
$newstorageaccountname = "paulo1337storage"
New-AzureRMStorageAccount -StorageAccountName $newstorageaccountname -Location westeurope -Type "Premium_LRS"
Now, its time to install our Cluster Nodes on the top of this storage account:

Create Disks (Premium // SSD):
With Powershell Remoting, manage both servers from a management/jump box and run the bellow to add the machines to the data Domain, Windows Features, :
# On both servers:
POWERCFG.EXE /S SCHEME_MIN
Add-Computer -DomainName data.local -Credential paulo
Restart-Computer -force
#Add Windows Features to our environment
Install-WindowsFeature –Name Failover-Clustering,File-Services –IncludeManagementTools
New-Cluster -Name CloudSQLServer1337 -Node CloudSQL1337N1,CloudSQL1337N2 -StaticAddress -NoStorage
#Enable Storage Space Direct on the cluster
Enable-ClusterS2D
At this stage, we have all the features enabled, lets add some SSD drives to the servers, note here, that the size of the disc will influence the performance of the disk itself.
A disk <128 GB of Size will translate to a maximum troughtput of 100 MB/s while a disk > 512 GB will translate to a maximum troughtput of 250 MB/s , more details about this P10/20/30 in https://docs.microsoft.com/en-us/azure/storage/storage-premium-storage

After having a couple of disks created, it is time to start creating the VirtualDisks to be used by SQL Server:


At this stage we can use this storage to install our SQL Server Failover Cluster, independent of it being on premises or cloud!
Information about disk distribution by enclosure:

Doing a test with Diskspd, representative of what could be an OLTP Workload (75% reads + 25% writes) could easily reach a 250 MB/s throughput with a single file; with more parallel executions and different configurations, this numbers could sky-rocket but I would leave that for another time/article.

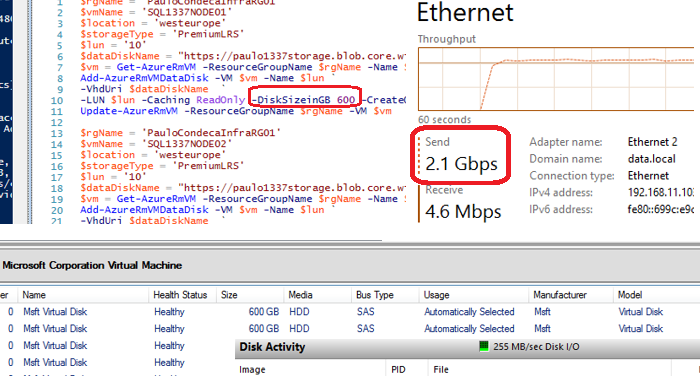
While this was running, I could see the network traffic between the nodes going on 🙂 inline with the WriteActivity (500 Mbps~62MB/s):

And out of curiosity, in one of the workloads, I took one of the nodes offline, just to see the network activity to put the volume in 100% healthy state, and it peaked with 2GBit/s , basically 250MB/s that translate the maximum troughput of a P30 disk.

This article is just to basically create awareness about this new Windows Server feature and how we could leverage it to benefit SQL Server implementations, so naturally, there are details that are not covered in this post.
I see some things happening in the future, such as:
- Something like Disk Type Awareness in VMs in Azure (SAS/SSD/NVMe), this is crucial for S2D to know automatically what disks are best used for caching purposes.
- Workloads running leveraging NVMe+RDMA+S2D for high throughput AO FCI running in the Cloud/ OnPremises.
All the best!
Paulo Condeça
