*1337 Tech alert: Azure, IaaS, IaC, SQL Server, AlwaysOn AG/FCI, Networking, Clustering, VPN Vnet2Vnet, S2D, SOFS, Load Balancers, Health Probes…
Helloooo! Besides SQL Server 🙂 On of my current professional personal pet projects is around Azure, I always liked Infrastructure/ networking related stuff; actually I was a SysAdmin back in 2004 managing stuff from DCs to Exchange, from networking to firewalls (hahahaha Checkpoint FW1 with NT4), back in the days when I had my own datacenter at home(where I hosted my domains and nameservers, e-mail server, web, ftp, I even hosted a private game server for Unreal Tournament for my friends), when I remember this stuff I just can’t avoid my ginormous smile… Bellow on of my servers back in 2002 in a Chieftec open chassis 😀

Back on track to the topic now, first of all, when we think about moving workloads to the cloud (actually, it is the same on-premises), there is one on point that based on my experience is often overlooked… It is the RTO (Repair Time Objective), that basically is, how long does it takes to bring the system up to a running state if shift happens.

What I bring today, is an end to end solution that can be used as an inspiration for a SQL Server(>=SQL2014) HA-DR architecture with Windows Server 2016; this concepts also apply outside of the SQL Server world and can be used in multiple scenarios…
First of all, the code used as example is in GitHub @ https://github.com/MrNetic/IaC , the scripts are numbered, so it is more intuitive to navigate, from 0 to xyz… Feel free to access this repo or/and be a contributor.
Moving forward, one of the things, that one must pay attention in Azure is in which subscription are the resources going to be created, always double check that the intended subscription is selected 🙂

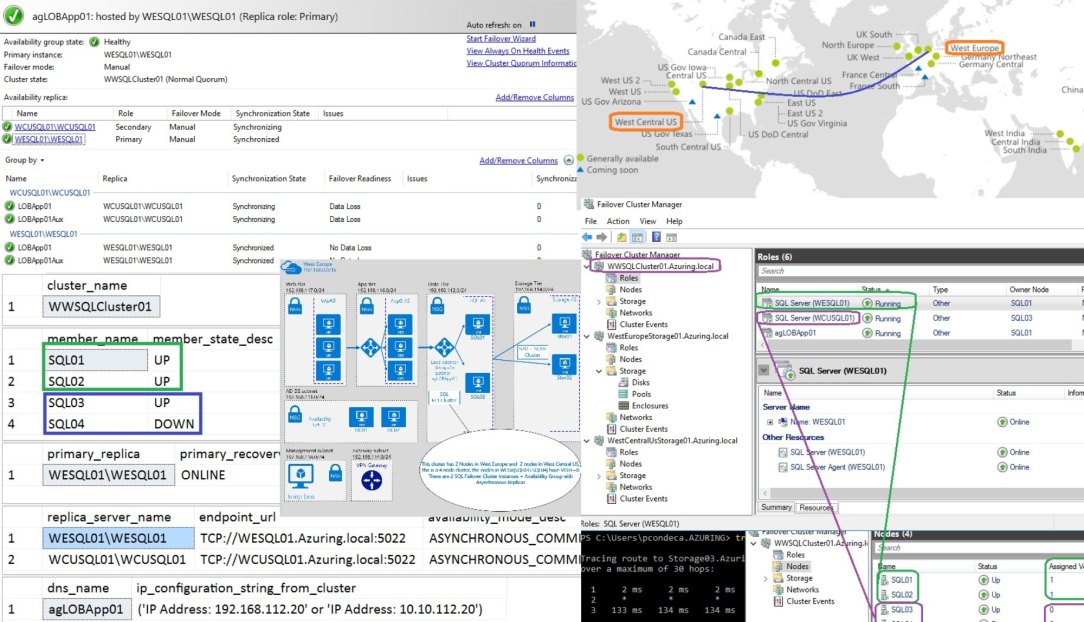
In this HA and DR scenario, our data will be spread and sync across 2 different Datacenters in different Azure Regions (West Europe and West Central Us ), they will talk each other with Vnet2Vnet VPN, this could also be an hybrid architecture between Azure and on-premises (or another cloud vendor such as AWS). Of course, that when developing a strategy like this, it shouldn’t be isolated just to database platforms of an organization; this mindset should true when dealing with the remaining infrastructure, software and processes :


For this architecture 3 Availability Sets(AS) per region should be created since we want the max isolation possible between the VMs, meaning DC’s in one AS, the SQL Server FCI nodes on different AS and our Storage Spaces Direct + Scale Out File Server (S2D+SOFS) configured on its own AS:

With this type of configuration both our Domain Controllers, SQL Servers nodes, and Storage nodes run in distinct availability sets; this is a strategy to handle planned and unplanned maintenance for the VMs (avoid running on the same rack/ network switch), meaning each VM will be assigned to an Update Domain (UD) split accross Fault Domains (FD) per AvailabilitySet (AS) :

Note: The maximum value for fault domains can be different between Azure regions!
Also, regarding network, per VNET it will be segmented in 6 different subnets, one for DCs/ Infrastructure, Management, Gateway, Storage and SQL Server (where the Availability Group Listener will be, note: an availability group can have multiple listener on multiple IPs if needed) ; an extra network interface will be configured at the SQL Server nodes and will be used for cluster communications, and AlwaysOn AG data synchronization (on it’s own subnet).
2 VNETs will be created, one for each region:

Bellow is a very high level architecture (x2, per site connected by Vnet2Vnet VPN)


After the VM’s are created and the pre-requisites are in place (domain services/ cloud witness for the clusters…) it is time to progress and create the clusters!
Our first pair of nodes are for the Storage Cluster in West Europe, basically they will serve the storage needs of the environment, started with only 2 nodes but can scale-up (like more RAM/CPU/SSD) and/or scale-out for more power and/or capacity with Storage Spaces Direct aka S2D and Scale-out Fileserver aka SOFS.


Also, with the type of architecture above for storage, we can leverage RAM for cache. (note: Azure has recently enabled RDMA-capable VMs to communicate each other over an InfiniBand network for compute intensive workloads).
After we have the storage running, it is just a typical SQL Server FCI installation on the other 2 nodes, but instead of using shared disks, SMB shares will be used (3.0) (note: there are multiple approaches here, such as using local storage for TEMPDB (or not), using multiple network interfaces to handle traffic and/or increase fault tolerance (or not), etc…).
The picture bellow shows the GEO-Cluster with Nodes both in Europe and US, the Disaster Recovery is in US (node vote =0)

Long story short, next step is to create a Vnet2VnetVPN and add 2 SQL nodes (running their own SQL Server Instance) in West Central Us and create another cluster (S2D+SOFS) in West Central Us (remember the sample scripts are maintained in GitHub @ https://github.com/MrNetic/IaC)

Next Steps:
Configure internal Load Balancers for: each FCI instance + HADR Endpoints + AG Listener
This will lead to the architecture bellow:

Take in consideration that one the most critical part when defining an environment like this is the planning, so it is very important to spend time there because not all components can be easily re-configured.
Hope you find this useful and let me know if you intend use it as an inspiration for an upcoming project!
All the best,
Paulo Condeça
